Deeper Study Into the WWW’s Document Object Model
The Document Object Model is a fundamental part of the World Wide Web. DOM for short, this is a set of API standards which define how a browser should construct a web document and how developers are able to manipulate objects.
We’ll be looking a bit further into how the DOM really works. The model has been around for years and currently resides at DOM level 3 (DOM3 documentation here). There is a DOM4 currently in editor’s draft with some brand new specs coming soon. For now we can focus on a brief understanding of how the object model came into being.
A History Lesson
During the early days of web scripting there was no standard way to access page objects. This allowed major browsers to come in and write their own standards and rules for document manipulation. Software companies even wrote their own Scripting languages such as VBScript by Microsoft and Applescript by Apple.
The early models were very limited. You could only access specific elements like images or form inputs. Over time the World Wide Web Consortium developed a standard model which most mainstream software publishers followed. Notably Microsoft’s Internet Explorer, Netscape, Safari, and Opera.

Currently the DOM has been through many revisions and allows for very precise manipulation of page elements. With script libraries such as jQuery and MooTools developers are able to spend much less time hung up on bugs.
Modern DOM Scripting Today
JavaScript is by far the most popular language amongst developers. Originally started as an open source project by Netscape in 1995. It’s based off the popular programming language Java and has been modified by countless communities of web developers.
The DOM itself is only useful in situations when objects are able to be accessed. Mostly all standards compliant browsers today support all elements and methods for DOM manipulation in full. With this standardization of the object model we have seen a rise in simple scripting and page functionality.
The Document Tree
When envisioning the DOM it can be easily understood in comparison to a tree. When a document loads each page element is held in memory as a new object. These are sometimes referred to as nodes of the tree.
As an example each proper HTML page should start with an HTML element and all page content should load within a body element. This means your tree hierarchy starts at a root HTML element and traverses into its first node body.
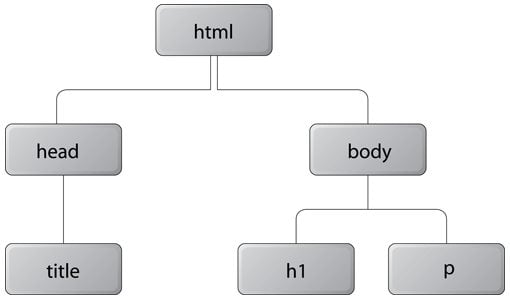
This is a simple idea but it provides immense power to developers. From this we are able to pull many types of elements from the page just by accessing their specific node or location in the document. A small script could be written to pull all images from a page and push them into an array for storage.
From here it’s possible to access each image element via JavaScript. Below I’ve added some code which sets 2 variables. The first holds the 3rd image object in memory while the second pulls the src string from the element.
var imgtag = document.images[3];
var imgsrc = document.images[3].src;
[/code]Node Methods
Once you have the ability to manipulate and access nodes you are able to push functions onto them. The Object Model is not just for traversing the page but also applying new effects.
These are called methods and they are written into the DOM specification. When imagining a node-based tree system these methods will clear up most any confusion. Below is a small example list of some popular methods you can use on nodes:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
Most of these methods can be used within a variable declaration or function return statement. They will return an object from the DOM in relation to your current placement.
The first two will grab the first inner node and last inner node, respectively. This is what the keyword child is supposed to represent, with nodeA being the parent to both children. This should also explain how parentNode works as you can pull the node object which sits directly above your current selector.

Both sibling functions are unbeknownst to most and target elements at the same hierarchical level. As an example if you were traversing an unordered list with 3 li tags you could only call nextSibling 2 times before returning null. Many of these functions have since become scaled down by 3rd party libraries into quicker, more accurate methods.
Element Classes and IDs
One of the most popular ways to retrieve object information is through direct targeting. If you've written HTML code you should know about class and ID attributes. These can be set on any page element and are notoriously useful for applying CSS styles.

When you create these attributes the DOM recognizes them as separate environments from the overall document. IDs are required to be unique amongst your page and will cause errors in scripting if you duplicate the same name. Classes may contain countless elements, although they can become bogged down quickly.
The popular method getElementById() has been used by developers for a decade to simplify the process of object manipulation. This method takes a single string argument which holds the ID value of any element you're looking to target. As such you can change an image's src attribute quickly with similar code:
document.getElementById('myImg').src = "images/newImg.jpg";
[/code]
Advances in the Model
With the release of the popular jQuery library it's easier than ever to develop powerful scripts. Older functions such as getElementById() and getElementsByTagName() are still accessible, though deprecated by most standards.
The quickest way to get started manipulating the DOM is by accessing objects through jQuery. A simple method call $(document).ready({}) is all that's required to run a new event. The $() syntax is used to represent pulling any type of object from the page.

This can be used in unison to pull IDs and tags from a page. Each simply requires the same symbols used in CSS declarations such as $('#myid') and $('.myclass'). Once inside the ready function jQuery allows you to pull out as many events and functions as you need.
The library is optimized for speed and with the DOM currently advancing rapidly we are seeing huge leaps in scripting support. Each node is loaded into an object memory slot which both the web browser and developer may access.
Conclusion
The open source movement has largely contributed to the advancement of DOM specs, too. Over the past 10 years we've seen XML welcomed into the documentation along with ways of defining content feeds (RSS, Atom, etc).
It's important to stay on top of trends as web developer. The web is advancing quickly and the Document Object Model's latest revisions show how much control is available today. If you'd like to delve further into DOM scripting we offer collections of jQuery tricks and many web design video tutorials completely free!